MySql索引的作用以及對索引的理解
索引是與效率掛鉤的,所以沒有索引,可能會存在問題
索引:提高數(shù)據(jù)庫的性能,索引是物美價(jià)廉的東西了。不用加內(nèi)存,不用改程序,不用調(diào)sql,只要執(zhí)行正確的 create index ,查詢速度就可能提高成百上千倍。但是天下沒有免費(fèi)的午餐,查詢速度的提高是以插入、更新、刪除的速度為代價(jià)的,這些寫操作,增加了大量的IO。所以它的價(jià)值,在于提高一個海量數(shù)據(jù)的檢索速度。
MySQL的服務(wù)器,本質(zhì)是在內(nèi)存中的,所有的數(shù)據(jù)庫的CURD操作,全部都是在內(nèi)存中進(jìn)行的!所以索引也是如此
提高算法效率的因素:
1.組織數(shù)據(jù)的方式
2.算法本身。
常見的索引分為以下幾種
主鍵索引(primary key)唯一索引(unique)普通索引(index)全文索引(fulltext)–解決中子文索引問題
創(chuàng)建一個海量表,在查詢的時候,沒有索引時看一下會有什么問題
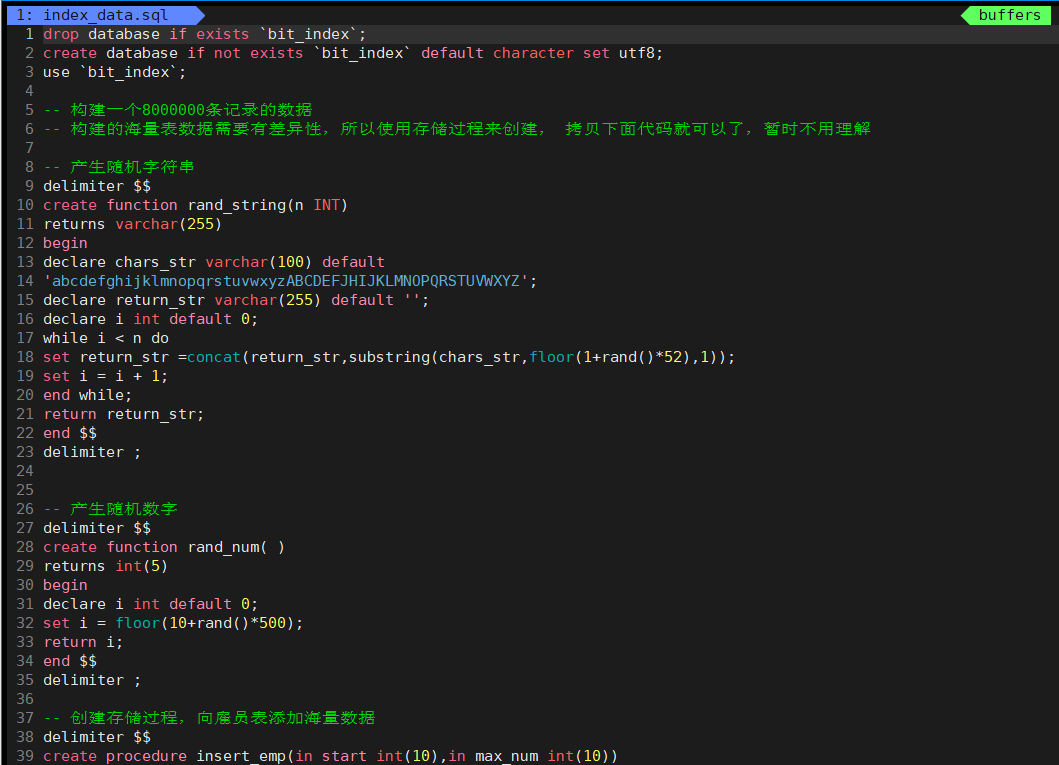
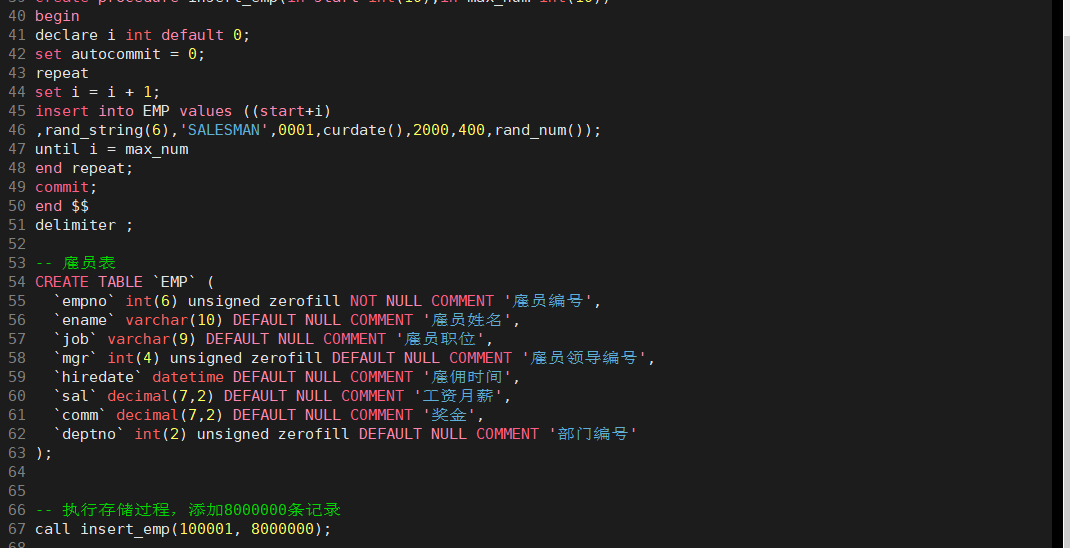
查詢員工編號為998877的員工
select * from EMP where empno=998877;
可以看到耗時17.71秒,這還是在本機(jī)一個人來操作,在實(shí)際項(xiàng)目中,如果放在公網(wǎng)中,假如同時有1000個人并發(fā)查詢,那很可能就死機(jī),這是非常可怕的事情。
解決方法,創(chuàng)建索引
alter table EMP add index(empno);
測試看查詢時間
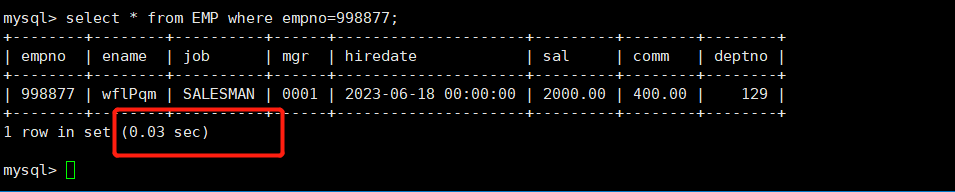
時間變得非常快!這就是索引帶來的好處!
想認(rèn)識索引之前,我們非常有必要先了解一下磁盤。
認(rèn)識磁盤mysql與存儲MySQL 給用戶提供存儲服務(wù),而存儲的都是數(shù)據(jù),數(shù)據(jù)在磁盤這個外設(shè)當(dāng)中。磁盤是計(jì)算機(jī)中的一個機(jī)械設(shè)備,相比于計(jì)算機(jī)其他電子元件,磁盤效率是比較低的,在加上IO本身的特征,可以知道,如何提交效率,是 MySQL 的一個重要話題。

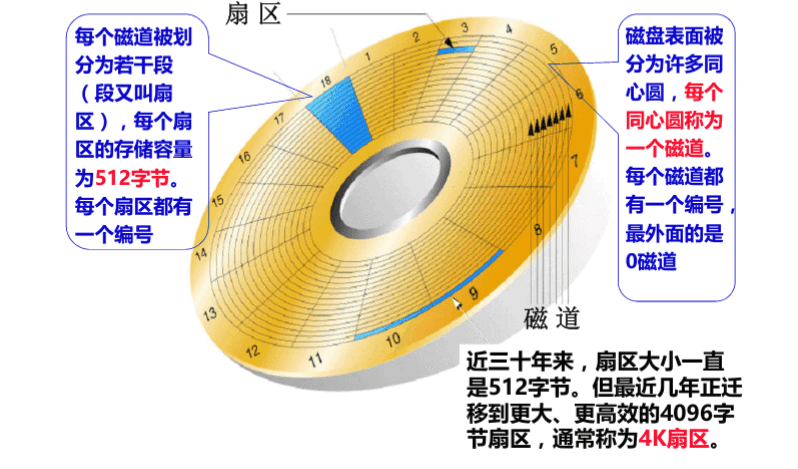
數(shù)據(jù)庫文件,本質(zhì)其實(shí)就是保存在磁盤的盤片當(dāng)中。也就是上面的一個個小格子中,就是我們經(jīng)常所說的扇區(qū)。當(dāng)然,數(shù)據(jù)庫文件很大,也很多,一定需要占據(jù)多個扇區(qū)
我們在使用Linux,所看到的大部分目錄或者文件,其實(shí)就是保存在硬盤當(dāng)中的。(當(dāng)然,有一些內(nèi)存文件系統(tǒng),如: proc , sys 之類,我們不考慮)
所以,最基本的,找到一個文件的全部,本質(zhì),就是在磁盤找到所有保存文件的扇區(qū)。而我們能夠定位任何一個扇區(qū),那么便能找到所有扇區(qū),因?yàn)椴檎曳绞绞且粯拥?/p>定位扇區(qū)
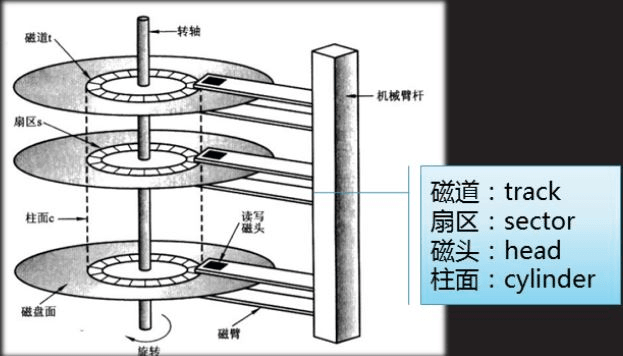
柱面(磁道): 多盤磁盤,每盤都是雙面,大小完全相等。那么同半徑的磁道,整體上便構(gòu)成了一個柱面
每個盤面都有一個磁頭,那么磁頭和盤面的對應(yīng)關(guān)系便是1對1的
所以,我們只需要知道,磁頭(Heads)、柱面(Cylinder)(等價(jià)于磁道)、扇區(qū)(Sector)對應(yīng)的編號。即可在磁盤上定位所要訪問的扇區(qū)。這種磁盤數(shù)據(jù)定位方式叫做 CHS 。不過實(shí)際系統(tǒng)軟件使用的并不是 CHS (但是硬件是),而是 LBA ,一種線性地址,可以想象成虛擬地址與物理地址。系統(tǒng)將 LBA 地址最后會轉(zhuǎn)化成為 CHS ,交給磁盤去進(jìn)行數(shù)據(jù)讀取。不過,我們現(xiàn)在不關(guān)心轉(zhuǎn)化細(xì)節(jié)。
結(jié)論我們現(xiàn)在已經(jīng)能夠在硬件層面定位,任何一個基本數(shù)據(jù)塊了(扇區(qū))。但是在系統(tǒng)軟件上,就不是直接按照扇區(qū)(512字節(jié),部分4096字節(jié)),進(jìn)行IO交互了,這是因?yàn)槿绻僮飨到y(tǒng)直接使用硬件提供的數(shù)據(jù)大小進(jìn)行交互,那么系統(tǒng)的IO代碼,就和硬件強(qiáng)相關(guān),換言之,如果硬件發(fā)生變化,系統(tǒng)必須跟著變化;另外目前來看,單次IO 512字節(jié),還是太小了。IO單位小,意味著讀取同樣的數(shù)據(jù)內(nèi)容,需要進(jìn)行多次磁盤訪問,會帶來效率的降低;
文件系統(tǒng)讀取基本單位,就不是扇區(qū),而是數(shù)據(jù)塊。既系統(tǒng)讀取磁盤,是以塊為單位的,基本單位是 4KB
磁盤隨機(jī)訪問(Random Access)與連續(xù)訪問(Sequential Access)隨機(jī)訪問:本次IO所給出的扇區(qū)地址和上次IO給出扇區(qū)地址不連續(xù),這樣的話磁頭在兩次IO操作之間需要作比較大的移動動作才能重新開始讀/寫數(shù)據(jù)。連續(xù)訪問:如果當(dāng)次IO給出的扇區(qū)地址與上次IO結(jié)束的扇區(qū)地址是連續(xù)的,那磁頭就能很快的開始這次IO操作,這樣的多個IO操作稱為連續(xù)訪問。因此盡管相鄰的兩次IO操作在同一時刻發(fā)出,但如果它們的請求的扇區(qū)地址相差很大的話也只能稱為隨機(jī)訪問,而非連續(xù)訪問。磁盤是通過機(jī)械運(yùn)動進(jìn)行尋址的,隨機(jī)訪問不需要過多的定位,故效率比較高
MySql 與磁盤交互基本單位PageMySql 作為一款應(yīng)用軟件,可以想象成一種特殊的文件系統(tǒng)。它有著更高的IO場景,所以,為了提高基本的IO效率, MySql 進(jìn)行IO的基本單位是16KB:MySql是應(yīng)用層服務(wù),是不可能直接訪問硬件的,這個16KB是站在MySql角度向OS提出來的,OS內(nèi)部存在文件緩沖區(qū)的,MySql進(jìn)入到某一個目錄,對某張表做CURD,對某張表內(nèi)部做增刪查改,在MySql就得到了文件的fd,一個文件被打開有自己的結(jié)構(gòu)體,緩沖區(qū);MySql以16KB為單位與文件緩沖區(qū)進(jìn)行IO。
show global status like 'innodb_page_size';-- 16382/1024=16KB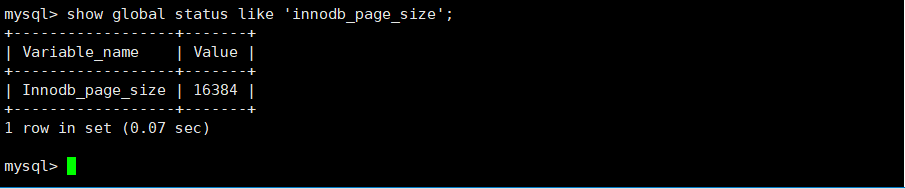
也就是說,磁盤這個硬件設(shè)備的基本單位是 512 字節(jié),而 MySQL InnoDB引擎 使用 16KB 進(jìn)行IO交互。即, MySQL 和磁盤進(jìn)行數(shù)據(jù)交互的基本單位是 16KB 。這個基本數(shù)據(jù)單元,在 MySQL 這里叫做page(注意和系統(tǒng)的page區(qū)分)
共識MySQL 中的數(shù)據(jù)文件,是以page為單位保存在磁盤當(dāng)中的。
MySQL 的 CURD 操作,都需要通過計(jì)算,找到對應(yīng)的插入位置,或者找到對應(yīng)要修改或者查詢的數(shù)據(jù)
只要涉及計(jì)算,就需要CPU參與,而為了便于CPU參與,一定要能夠先將數(shù)據(jù)移動到內(nèi)存當(dāng)中
所以在特定時間內(nèi),數(shù)據(jù)一定是磁盤中有,內(nèi)存中也有。后續(xù)操作完內(nèi)存數(shù)據(jù)之后,以特定的刷新策略,刷新到磁盤。而這時,就涉及到磁盤和內(nèi)存的數(shù)據(jù)交互,也就是IO。此時IO的基本單位就是Page。
為了更好的進(jìn)行上面的操作, MySQL 服務(wù)器在內(nèi)存中運(yùn)行的時候,在服務(wù)器內(nèi)部,就申請了被稱為 Buffer Pool 的的大內(nèi)存空間,來進(jìn)行各種緩存。其實(shí)就是很大的內(nèi)存空間,來和磁盤數(shù)據(jù)進(jìn)行IO交互
為了更高的效率,一定要盡可能的減少系統(tǒng)和磁盤IO的次數(shù)
索引的理解創(chuàng)建一張表:
create table if not exists user (id int primary key, age int not null,name varchar(16) not null);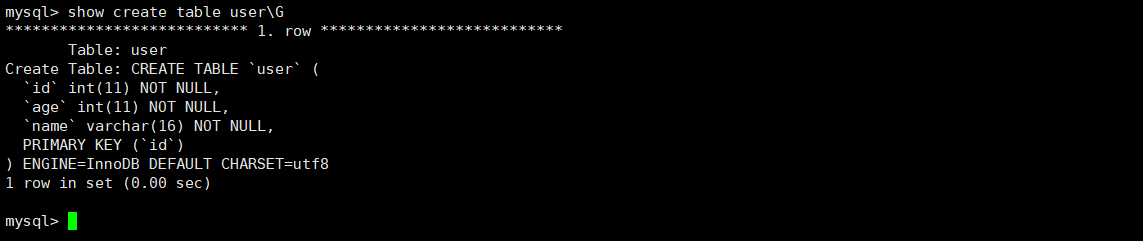
現(xiàn)在往表里插入5條數(shù)據(jù),結(jié)果如下:插入的數(shù)據(jù)是無序的,但是查看結(jié)果卻是有序的!
mysql> insert into user (id, age, name) values(3, 18, '楊過');Query OK, 1 row affected (0.00 sec)mysql> insert into user (id, age, name) values(4, 16, '小龍女');Query OK, 1 row affected (0.04 sec)mysql> insert into user (id, age, name) values(2, 26, '黃蓉');Query OK, 1 row affected (0.03 sec)mysql> insert into user (id, age, name) values(5, 36, '郭靖');Query OK, 1 row affected (0.02 sec)mysql> insert into user (id, age, name) values(1, 56, '歐陽鋒');Query OK, 1 row affected (0.03 sec)
我們向一個具有主鍵的表中,亂序插入數(shù)據(jù),發(fā)現(xiàn)數(shù)據(jù)會自動排序,這是誰做的,為什么要這樣做?
對于這個問題的回答,我們來看一看。
首先磁盤上有對應(yīng)的文件數(shù)據(jù),文件數(shù)據(jù)最終會被預(yù)讀到文件緩沖區(qū),mysql啟動的時候會申請buffer pool,mysql層面上,所有的page都會被放到buffer pool中,理解mysql中page的概念:一個page是16KB,mysql內(nèi)部一定需要并且會存在大量的page,也就決定了mysql必須要將多個同時存在的page管理起來。要管理所有的mysql內(nèi)的page,需要先描述,在組織,所以不要簡單將page認(rèn)為是一個內(nèi)存塊,page內(nèi)部也必須寫入對應(yīng)的管理信息!如:
struct page{struct page*next;struct page*prev;char buffer[NUM];};-- 16KB,所謂的申請,在mysql申請的page就是new page,在用簡單的方式:比如將所有的page用鏈表的形式管理起來。在buffer pool內(nèi)部,對mysql中的page進(jìn)行了一個建模。
了解一下:MySQL和磁盤進(jìn)行IO交互的時候,采用Page的方案進(jìn)行交互
為什么MySQL和磁盤進(jìn)行IO交互的時候,要采用Page的方案進(jìn)行交互?用多少,加載多少不可以嗎?如上面的5條記錄,如果MySQL要查找id=2的記錄,第一次加載id=1,第二次加載id=2,一次一條記錄,那么就需要2次IO。如果要找id=5,那么就需要5次IO。但,如果這5條(或者更多)都被保存在一個Page中(16KB,能保存很多記錄),那么第一次IO查找id=2的時候,整個Page會被加載到MySQL的Buffer Pool中,這里完成了一次IO。但是往后如果在查找id=1,3,4,5等,完全不需要進(jìn)行IO了,而是直接在內(nèi)存中進(jìn)行了。所以,就在單Page里面,大大減少了IO的次數(shù)。
怎么保證,用戶一定下次找的數(shù)據(jù),就在這個Page里面?我們不能嚴(yán)格保證,但是有很大概率,因?yàn)橛芯植啃栽怼M鵌O效率低下的最主要矛盾不是IO單次數(shù)據(jù)量的大小,而是IO的次數(shù)
理解單個PageMySQL 中要管理很多數(shù)據(jù)表文件,而要管理好這些文件,就需要先描述,在組織 ,我們目前可以簡單理解成一個個獨(dú)立文件是有一個或者多個Page構(gòu)成的,這在我們一開始也有說到
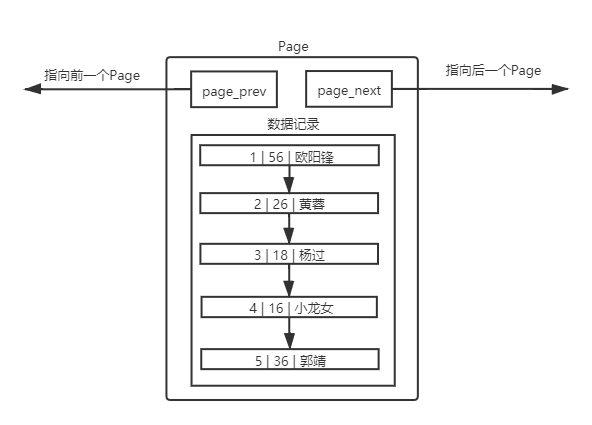
對于不同的 Page ,在 MySQL 中,都是 16KB ,使用 prev 和 next 構(gòu)成雙向鏈表因?yàn)橛兄麈I的問題, MySQL 會默認(rèn)按照主鍵給我們的數(shù)據(jù)進(jìn)行排序,從上面的Page內(nèi)數(shù)據(jù)記錄可以看出,數(shù)據(jù)是有序且彼此關(guān)聯(lián)的。
**插入數(shù)據(jù)時排序的目的,就是優(yōu)化查詢的效率。**頁內(nèi)部存放數(shù)據(jù)的模塊,實(shí)質(zhì)上也是一個鏈表的結(jié)構(gòu),鏈表的特點(diǎn)也就是增刪快,查詢修改慢,所以優(yōu)化查詢的效率是必須的。正式因?yàn)橛行颍诓檎业臅r候,從頭到后都是有效查找,沒有任何一個查找是浪費(fèi)的,而且,如果運(yùn)氣好,是可以提前結(jié)束查找過程的。
理解多個Page上面頁模式中,只有一個功能,就是在查詢某條數(shù)據(jù)的時候直接將一整頁的數(shù)據(jù)加載到內(nèi)存中,以減少硬盤IO次數(shù),從而提高性能。但是,我們也可以看到,現(xiàn)在的頁模式內(nèi)部,實(shí)際上是采用了鏈表的結(jié)構(gòu),前一條數(shù)據(jù)指向后一條數(shù)據(jù),本質(zhì)上還是通過數(shù)據(jù)的逐條比較來取出特定的數(shù)據(jù);如果有1千萬條數(shù)據(jù),一定需要多個Page來保存1千萬條數(shù)據(jù),多個Page彼此使用雙鏈表鏈接起來,而且每個Page內(nèi)部的數(shù)據(jù)也是基于鏈表的。那么,查找特定一條記錄,也一定是線性查找。效率也太低了。
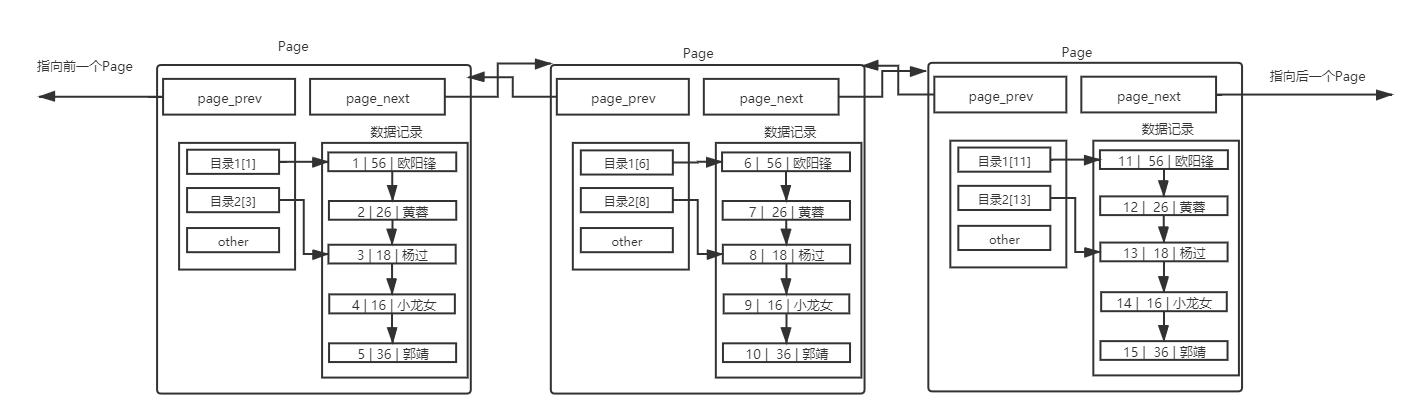
所以要提高效率,我們要有兩個角度進(jìn)行考量:第一個角度是在單page的時候如何提高一個Page內(nèi)部的鏈?zhǔn)奖闅v的效率;另一個是多Page的時候怎么解決Page間進(jìn)行查找的效率。所以我們有了頁目錄的出現(xiàn)。
頁目錄比如我們在看《軟件工程導(dǎo)論》這本書的時候,如果我們要看軟件生命周期這個章節(jié),找到該章節(jié)有兩種做法從頭逐頁的向后翻,直到找到目標(biāo)內(nèi)容;通過書提供的目錄,發(fā)現(xiàn)軟件生命周期章節(jié)在11頁(假設(shè)),那么我們便直接翻到11頁。同時,查找目錄的方案,可以順序找,不過因?yàn)槟夸浀捻摂?shù)肯定少,所以可以快速提高定位本質(zhì)上,書中的目錄,是多花了紙張的,但是卻提高了效率;所以,目錄,是一種“空間換時間的做法”
單頁情況對于上面的單頁P(yáng)age,我們也可以引入目錄
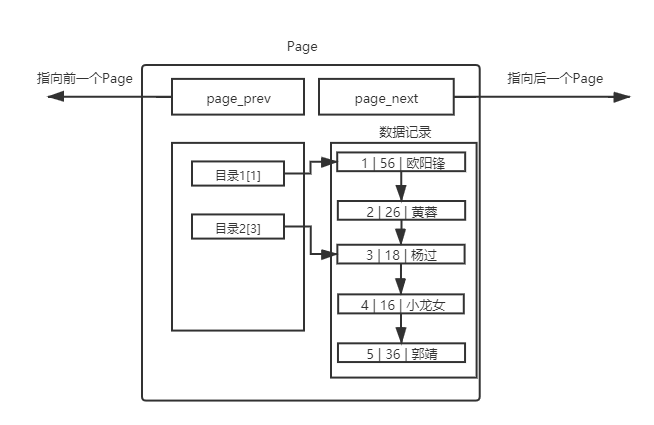
在一個Page內(nèi)部,我們引入了目錄。比如,我們要查找id=4記錄,之前必須線性遍歷4次,才能拿到結(jié)果。現(xiàn)在直接通過目錄2[3],直接進(jìn)行定位新的起始位置,提高了效率。
所以對于一開始的問題,我們可以正式回答了:主鍵插入無序的,但是結(jié)果是有序的,很簡單,只有把數(shù)據(jù)變成有序的,能夠方便我們引入頁內(nèi)目錄!
多頁情況MySQL 中每一頁的大小只有 16KB ,單個Page大小固定,所以隨著數(shù)據(jù)量不斷增大, 16KB 不可能存下所有的數(shù)據(jù),那么必定會有多個頁來存儲數(shù)據(jù)。
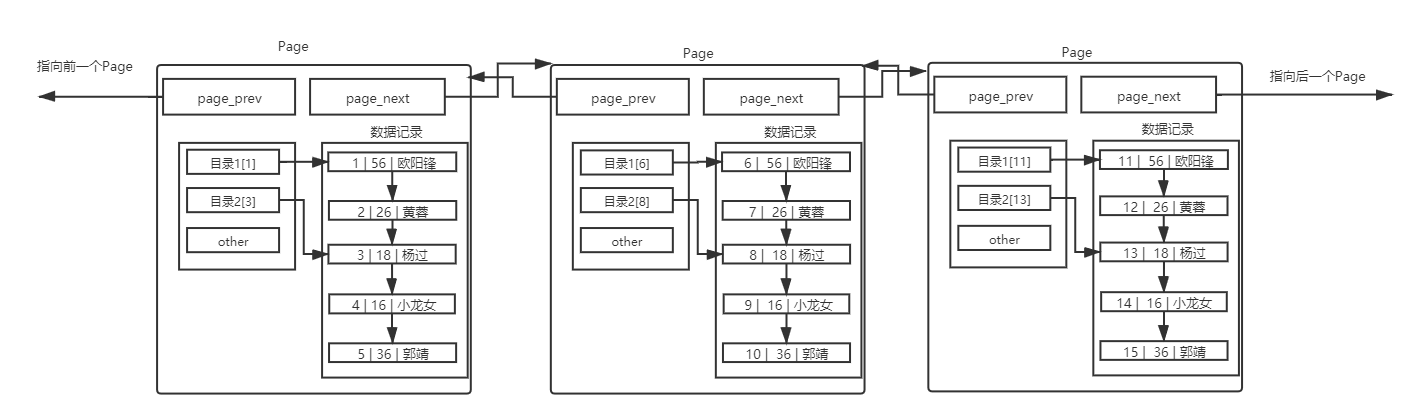
在單表數(shù)據(jù)不斷被插入的情況下, MySQL 會在容量不足的時候,自動開辟新的Page來保存新的數(shù)據(jù),然后通過指針的方式,將所有的Page組織起來 對于上面的圖,是理想結(jié)構(gòu),要保證整體有序,那么新插入的數(shù)據(jù),不一定會在新Page上面,這里僅僅做演示。這樣,我們就可以通過多個Page遍歷,Page內(nèi)部通過目錄來快速定位數(shù)據(jù)。可是,這樣也有效率問題,在Page之間,也是需要 MySQL 遍歷的,遍歷意味著依舊需要進(jìn)行大量的IO,將下一個Page加載到內(nèi)存,進(jìn)行線性檢測。這樣就顯得我們之前的Page內(nèi)部的目錄,作用沒那么大了。
所以,我們給Page也帶上目錄。
使用一個目錄項(xiàng)來指向某一頁,而這個目錄項(xiàng)存放的就是將要指向的頁中存放的最小數(shù)據(jù)的鍵值。和頁內(nèi)目錄不同的地方在于,這種目錄管理的級別是頁,而頁內(nèi)目錄管理的級別是行。其中,每個目錄項(xiàng)的構(gòu)成是:鍵值+指針。
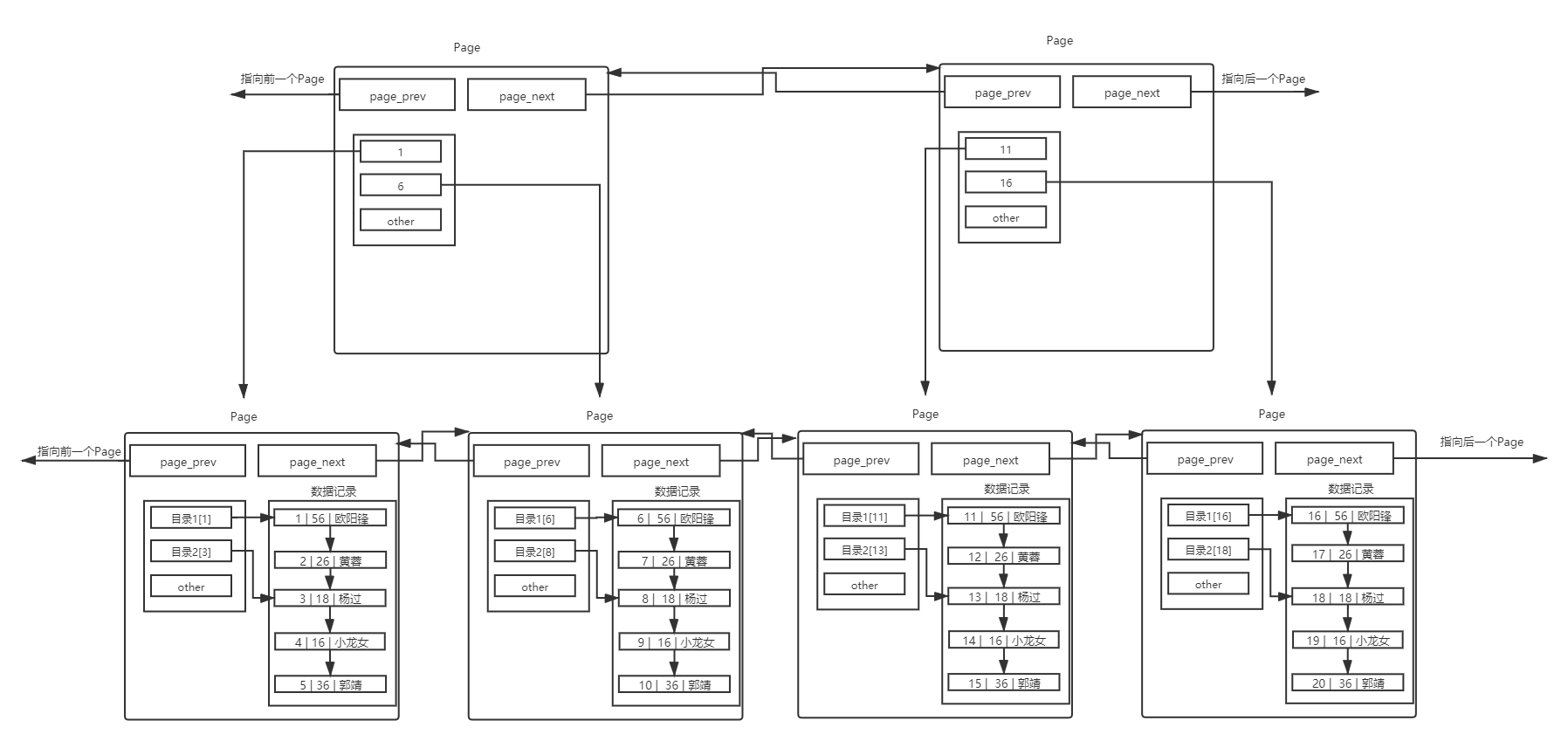
存在一個目錄頁來管理頁目錄,目錄頁中的數(shù)據(jù)存放的就是指向的那一頁中最小的數(shù)據(jù)。有數(shù)據(jù),就可通過比較,找到該訪問那個Page,進(jìn)而通過指針,找到下一個Page。其實(shí)目錄頁的本質(zhì)也是頁,普通頁中存的數(shù)據(jù)是用戶數(shù)據(jù),而目錄頁中存的數(shù)據(jù)是普通頁的地址。但是我們每次檢索數(shù)據(jù)的時候,應(yīng)該從哪里開始,雖然頂層的目錄頁少了,但是還需要遍歷,不用擔(dān)心,可以在加目錄頁,哈哈,你沒想錯!
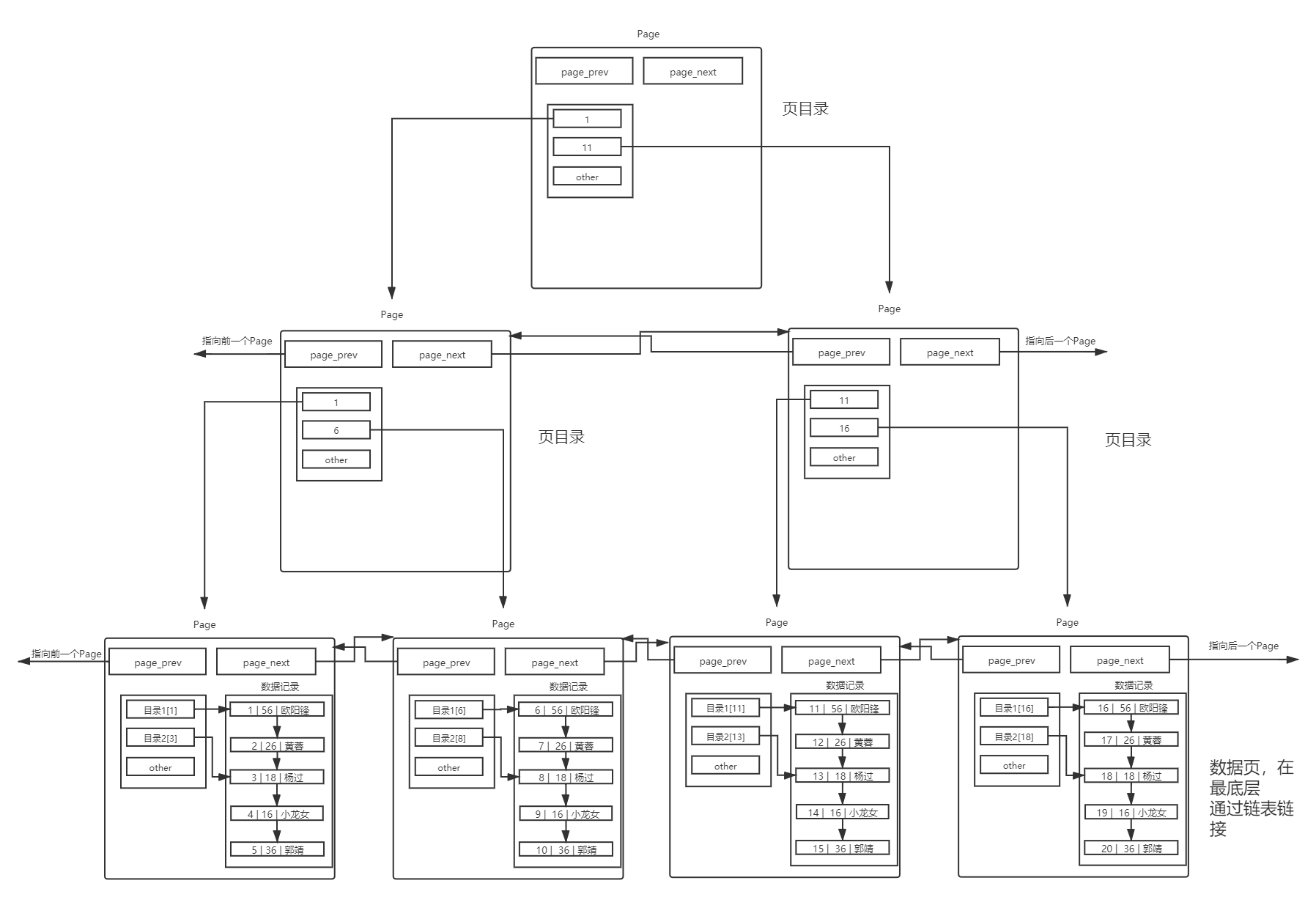
這就是傳說中的B+樹!把整個的B+樹稱作mysql innode db下的索引結(jié)構(gòu),一般我們建表的時候,就是在該結(jié)構(gòu)下進(jìn)行CURD,即使沒有主鍵也是這樣子的,會有默認(rèn)主鍵的至此,我們已經(jīng)給我們的表user構(gòu)建完了主鍵索引。隨便找一個id=?我們發(fā)現(xiàn),現(xiàn)在查找的Page數(shù)一定減少了,也就意味著IO次數(shù)減少了,那么效率也就提高了。
1.葉子節(jié)點(diǎn)保存有數(shù)據(jù),路上節(jié)點(diǎn)沒有,非葉子節(jié)點(diǎn),不要數(shù)據(jù),只要目錄項(xiàng)
非葉子節(jié)點(diǎn)不存數(shù)據(jù),可以存儲更多的目錄項(xiàng),目錄頁可以管理更多的葉子page,這棵樹一定是一個矮胖型的樹。這也意味著途徑的路上節(jié)點(diǎn)減少。這也意味著找到目標(biāo)數(shù)據(jù)只需要更少的page,也就是IO次數(shù)更少,在IO層面,提高了效率!
每一個節(jié)點(diǎn),都有目錄項(xiàng),可以大大提高搜索效率。
2.葉子節(jié)點(diǎn)全部用鏈表級聯(lián)起來
這是b+樹的特點(diǎn);我們比較希望進(jìn)行范圍查找
總結(jié)到此這篇關(guān)于MySql索引的作用以及對索引的理解的文章就介紹到這了,更多相關(guān)MySql索引作用及理解內(nèi)容請搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備