Mysql查詢優(yōu)化之IN子查詢優(yōu)化方法詳解
目錄
- 物化表
- 物化表轉(zhuǎn)連接
- 總結(jié)
物化表
首先提出一個(gè)不相關(guān)的IN子查詢
SELECT * FROM s1 WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = "a");
對(duì)于不相關(guān)的 IN 子查詢來(lái)說(shuō),如果子查詢的結(jié)果集中的記錄條數(shù)很少,那么把子查詢和外層
查詢分別看成兩個(gè)單獨(dú)的單表查詢效率還是蠻高的,但是如果單獨(dú)執(zhí)行子查詢后的結(jié)果集太多的話,就會(huì)導(dǎo)致這
些問(wèn)題:
- 結(jié)果集太多,可能內(nèi)存中都放不下~
- 對(duì)于外層查詢來(lái)說(shuō),如果子查詢的結(jié)果集太多,那就意味著 IN 子句中的參數(shù)特別多,這就導(dǎo)致:
無(wú)法有效的使用索引,只能對(duì)外層查詢進(jìn)行全表掃描。
在對(duì)外層查詢執(zhí)行全表掃描時(shí),由于 IN 子句中的參數(shù)太多,這會(huì)導(dǎo)致檢測(cè)一條記錄是否符合和 IN 子句中的參數(shù)匹配花費(fèi)的時(shí)間太長(zhǎng)。
比如說(shuō) IN 子句中的參數(shù)只有兩個(gè):
SELECT * FROM tbl_name WHERE column IN (a, b);
這樣相當(dāng)于需要對(duì) tbl_name 表中的每條記錄判斷一下它的 column 列是否符合 column = a OR column= b 。在 IN 子句中的參數(shù)比較少時(shí)這并不是什么問(wèn)題,如果 IN 子句中的參數(shù)比較多時(shí),比如這樣:
SELECT * FROM tbl_name WHERE column IN (a, b, c …, …);
那么這樣每條記錄需要判斷一下它的 column 列是否符合 column = a OR column = b OR column = c
OR … ,這樣性能耗費(fèi)可就多了。
所以提出一個(gè)解決方案:不直接將不相關(guān)子查詢的結(jié)果集當(dāng)作外層查詢的參數(shù),而是將該結(jié)果集寫(xiě)入一個(gè)臨時(shí)表里。
臨時(shí)表的特性:
- 該臨時(shí)表的列就是子查詢結(jié)果集中的列。
- 寫(xiě)入臨時(shí)表的記錄會(huì)被去重。
- 一般情況下子查詢結(jié)果集不會(huì)大的離譜,所以會(huì)為它建立基于內(nèi)存的使用 Memory 存儲(chǔ)引擎的臨時(shí)表,而且會(huì)為該表建立哈希索引。
- 如果子查詢的結(jié)果集非常大,超過(guò)了系統(tǒng)變量 tmp_table_size 或者 max_heap_table_size ,臨時(shí)表會(huì)轉(zhuǎn)而
使用基于磁盤的存儲(chǔ)引擎來(lái)保存結(jié)果集中的記錄,索引類型也對(duì)應(yīng)轉(zhuǎn)變?yōu)?B+ 樹(shù)索引。
這個(gè)將子查詢結(jié)果集中的記錄保存到臨時(shí)表的過(guò)程稱之為 物化。
物化表轉(zhuǎn)連接
當(dāng)我們把子查詢進(jìn)行物化之后,假設(shè)子查詢物化表的名稱為 materialized_table ,該物化表存儲(chǔ)的子查詢結(jié)果集的列為 m_val ,那么這個(gè)查詢其實(shí)可以從下邊兩種角度來(lái)看待:
SELECT * FROM s1WHERE key1 IN (SELECT common_field FROM s2 WHERE key3 = ‘a(chǎn)");
從表 s1 的角度來(lái)看待,整個(gè)查詢的意思其實(shí)是:對(duì)于 s1 表中的每條記錄來(lái)說(shuō),如果該記錄的 key1 列的值
在子查詢對(duì)應(yīng)的物化表中,則該記錄會(huì)被加入最終的結(jié)果集。畫(huà)個(gè)圖表示一下就是這樣:
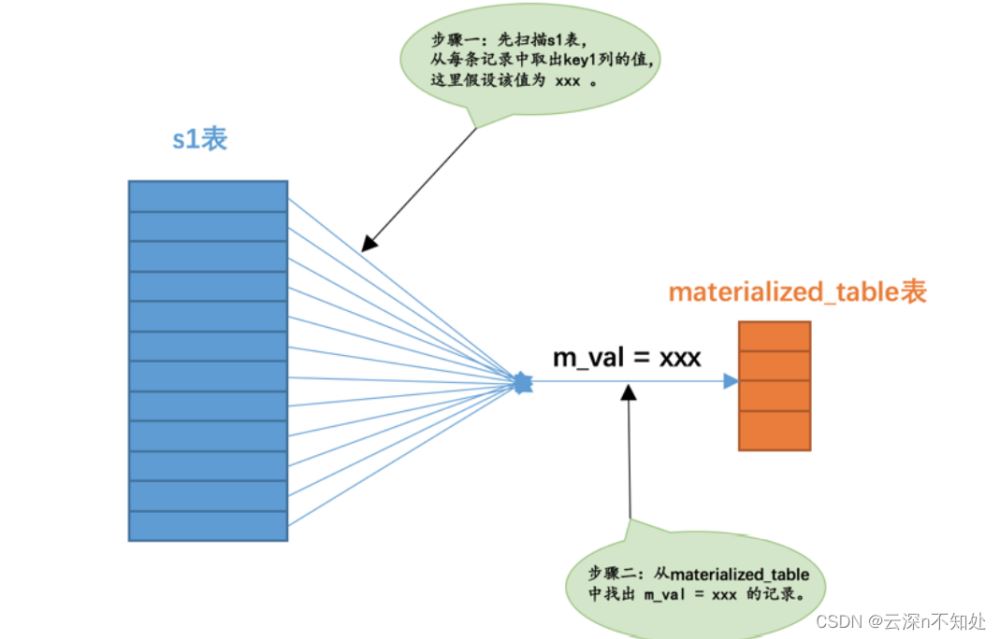
從子查詢物化表的角度來(lái)看待,整個(gè)查詢的意思其實(shí)是:對(duì)于子查詢物化表的每個(gè)值來(lái)說(shuō),如果能在 s1 表
中找到對(duì)應(yīng)的 key1 列的值與該值相等的記錄,那么就把這些記錄加入到最終的結(jié)果集。
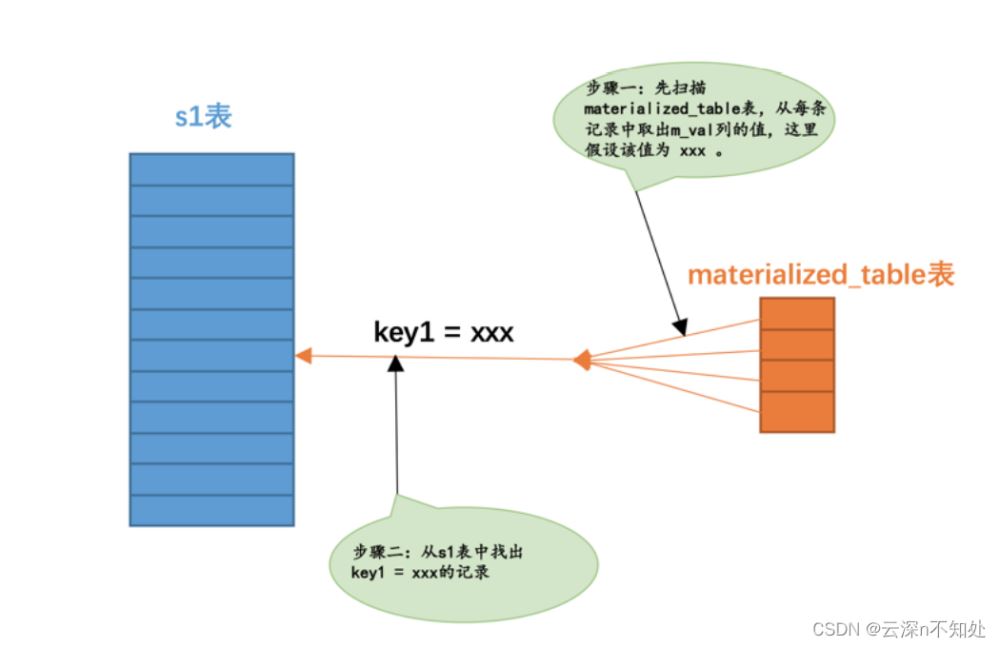
也就是說(shuō)其實(shí)上邊的查詢就相當(dāng)于表 s1 和子查詢物化表 materialized_table 進(jìn)行內(nèi)連接:
SELECT s1.* FROM s1 INNER JOIN materialized_table ON key1 = m_val;
如果使用 s1 表作為驅(qū)動(dòng)表的話,總查詢成本由下邊幾個(gè)部分組成:
- 物化子查詢時(shí)需要的成本
- 掃描 s1 表時(shí)的成本
- s1表中的記錄數(shù)量 × 通過(guò) m_val = xxx 對(duì) materialized_table 表進(jìn)行單表訪問(wèn)的成本(物化表中的記錄是不重復(fù)的,并且為物化表中的列建立了索引,所以這個(gè)步驟顯然是非常快的)。
如果使用 materialized_table 表作為驅(qū)動(dòng)表的話,總查詢成本由下邊幾個(gè)部分組成:
- 物化子查詢時(shí)需要的成本
- 掃描物化表時(shí)的成本
- 物化表中的記錄數(shù)量 × 通過(guò) key1 = xxx 對(duì) s1 表進(jìn)行單表訪問(wèn)的成本
總結(jié)
到此這篇關(guān)于Mysql查詢優(yōu)化之IN子查詢優(yōu)化方法的文章就介紹到這了,更多相關(guān)Mysql IN子查詢優(yōu)化內(nèi)容請(qǐng)搜索以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持!

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備