Python圖像識(shí)別+KNN求解數(shù)獨(dú)的實(shí)現(xiàn)
Python-opencv+KNN求解數(shù)獨(dú)
最近一直在玩數(shù)獨(dú),突發(fā)奇想實(shí)現(xiàn)圖像識(shí)別求解數(shù)獨(dú),輸入到輸出平均需要0.5s。
整體思路大概就是識(shí)別出圖中數(shù)字生成list,然后求解。
輸入輸出demo
數(shù)獨(dú)采用的是微軟自帶的Microsoft sudoku軟件隨便截取的圖像,如下圖所示:
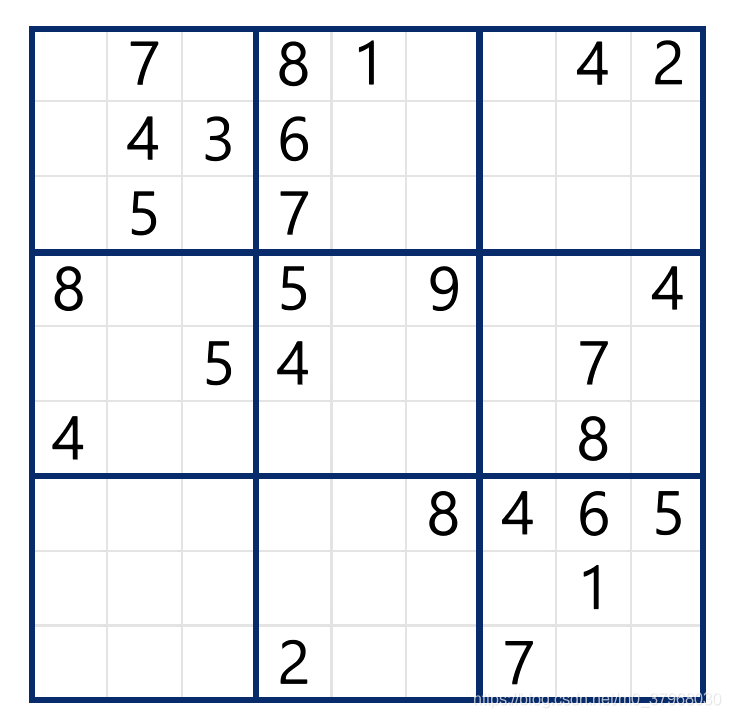
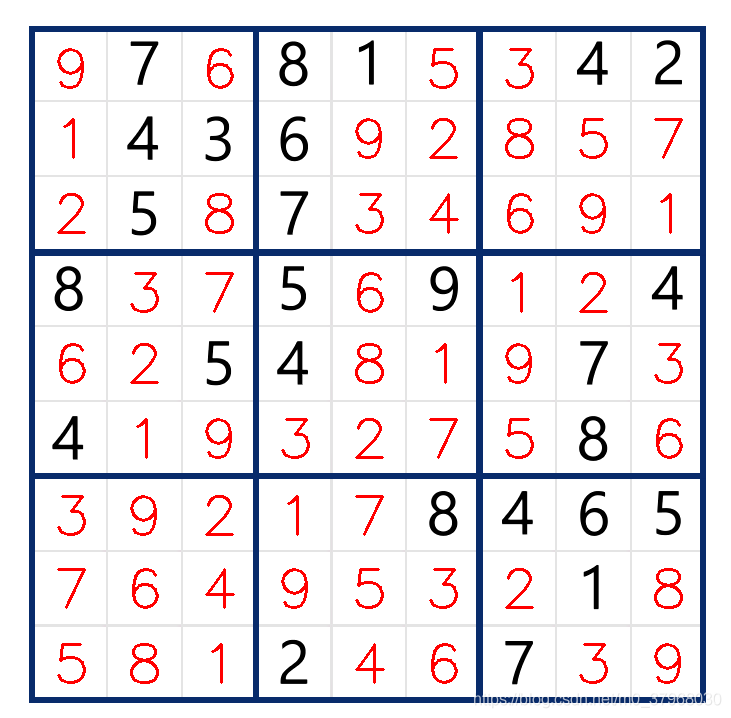
經(jīng)過程序求解后,得到的結(jié)果如下圖所示:
程序具體流程
程序整體流程如下圖所示:
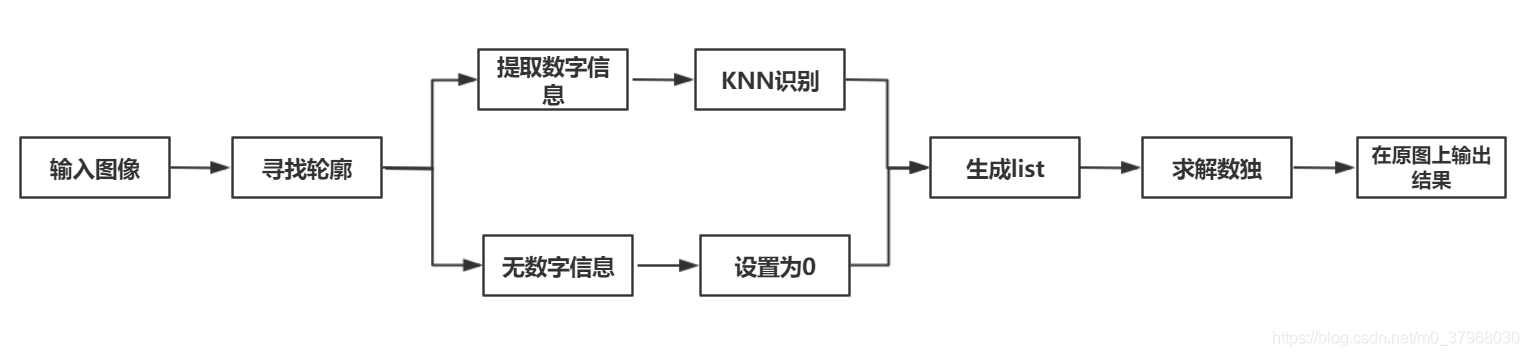
讀入圖像后,根據(jù)求解輪廓信息找到數(shù)字所在位置,以及不包含數(shù)字的空白位置,提取數(shù)字信息通過KNN識(shí)別,識(shí)別出數(shù)字;無數(shù)字信息的在list中置0;生成未求解數(shù)獨(dú)list,之后求解數(shù)獨(dú),將信息在原圖中顯示出來。
# -*-coding:utf-8-*-import osimport cv2 as cvimport numpy as npimport time#####################################################尋找數(shù)字生成listdef find_dig_(img, train_set): if img is None: print('無效的圖片!') os._exit(0) return _, thre = cv.threshold(img, 230, 250, cv.THRESH_BINARY_INV) _, contours, hierarchy = cv.findContours(thre, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE) sudoku_list = [] boxes = [] for i in range(len(hierarchy[0])): if hierarchy[0][i][3] == 0: # 表示父輪廓為 0 boxes.append(hierarchy[0][i]) # 提取數(shù)字 nm = [] for j in range(len(boxes)): # 此處len(boxes)=81 if boxes[j][2] != -1: x, y, w, h = cv.boundingRect(contours[boxes[j][2]]) nm.append([x, y, w, h]) # 在原圖中框選各個(gè)數(shù)字 cropped = img[y:y + h, x:x + w] im = img_pre(cropped)#預(yù)處理 AF = incise(im)#切割數(shù)字圖像 result = identification(train_set, AF, 7)#knn識(shí)別 sudoku_list.insert(0, int(result))#生成list else: sudoku_list.insert(0, 0)if len(sudoku_list) == 81: sudoku_list= np.array(sudoku_list) sudoku_list= sudoku_list.reshape((9, 9)) print('old_sudoku -> n', sudoku_list) return sudoku_list, contours, hierarchy else: print('無效的圖片!') os._exit(0)#######################################################KNN算法識(shí)別數(shù)字def img_pre(cropped): # 預(yù)處理數(shù)字圖像 im = np.array(cropped) # 轉(zhuǎn)化為二維數(shù)組 for i in range(im.shape[0]): # 轉(zhuǎn)化為二值矩陣 for j in range(im.shape[1]): # print(im[i, j]) if im[i, j] != 255:im[i, j] = 1 else:im[i, j] = 0 return im# 提取圖片特征def feature(A): midx = int(A.shape[1] / 2) + 1 midy = int(A.shape[0] / 2) + 1 A1 = A[0:midy, 0:midx].mean() A2 = A[midy:A.shape[0], 0:midx].mean() A3 = A[0:midy, midx:A.shape[1]].mean() A4 = A[midy:A.shape[0], midx:A.shape[1]].mean() A5 = A.mean() AF = [A1, A2, A3, A4, A5] return AF# 切割圖片并返回每個(gè)子圖片特征def incise(im): # 豎直切割并返回切割的坐標(biāo) a = []; b = [] if any(im[:, 0] == 1): a.append(0) for i in range(im.shape[1] - 1): if all(im[:, i] == 0) and any(im[:, i + 1] == 1): a.append(i + 1) elif any(im[:, i] == 1) and all(im[:, i + 1] == 0): b.append(i + 1) if any(im[:, im.shape[1] - 1] == 1): b.append(im.shape[1]) # 水平切割并返回分割圖片特征 names = locals(); AF = [] for i in range(len(a)): names[’na%s’ % i] = im[:, range(a[i], b[i])] if any(names[’na%s’ % i][0, :] == 1): c = 0 else: for j in range(names[’na%s’ % i].shape[0]):if j < names[’na%s’ % i].shape[0] - 1: if all(names[’na%s’ % i][j, :] == 0) and any(names[’na%s’ % i][j + 1, :] == 1): c = j breakelse: c = j if any(names[’na%s’ % i][names[’na%s’ % i].shape[0] - 1, :] == 1): d = names[’na%s’ % i].shape[0] - 1 else: for j in range(names[’na%s’ % i].shape[0]):if j < names[’na%s’ % i].shape[0] - 1: if any(names[’na%s’ % i][j, :] == 1) and all(names[’na%s’ % i][j + 1, :] == 0): d = j + 1 breakelse: d = j names[’na%s’ % i] = names[’na%s’ % i][range(c, d), :] AF.append(feature(names[’na%s’ % i])) # 提取特征 for j in names[’na%s’ % i]: pass return AF# 訓(xùn)練已知圖片的特征def training(): train_set = {} for i in range(9): value = [] for j in range(15): ima = cv.imread(’E:/test_image/knn_test/{}/{}.png’.format(i + 1, j + 1), 0) im = img_pre(ima) AF = incise(im) value.append(AF[0]) train_set[i + 1] = value return train_set# 計(jì)算兩向量的距離def distance(v1, v2): vector1 = np.array(v1) vector2 = np.array(v2) Vector = (vector1 - vector2) ** 2 distance = Vector.sum() ** 0.5 return distance# 用最近鄰算法識(shí)別單個(gè)數(shù)字def knn(train_set, V, k): key_sort = [11] * k value_sort = [11] * k for key in range(1, 10): for value in train_set[key]: d = distance(V, value) for i in range(k):if d < value_sort[i]: for j in range(k - 2, i - 1, -1): key_sort[j + 1] = key_sort[j] value_sort[j + 1] = value_sort[j] key_sort[i] = key value_sort[i] = d break max_key_count = -1 key_set = set(key_sort) for key in key_set: if max_key_count < key_sort.count(key): max_key_count = key_sort.count(key) max_key = key return max_key# 生成數(shù)字def identification(train_set, AF, k): result = ’’ for i in AF: key = knn(train_set, i, k) result = result + str(key) return result#############################################################################################################求解數(shù)獨(dú)def get_next(m, x, y): # 獲得下一個(gè)空白格在數(shù)獨(dú)中的坐標(biāo)。 :param m 數(shù)獨(dú)矩陣 :param x 空白格行數(shù) :param y 空白格列數(shù) ''' for next_y in range(y + 1, 9): # 下一個(gè)空白格和當(dāng)前格在一行的情況 if m[x][next_y] == 0: return x, next_y for next_x in range(x + 1, 9): # 下一個(gè)空白格和當(dāng)前格不在一行的情況 for next_y in range(0, 9): if m[next_x][next_y] == 0:return next_x, next_y return -1, -1 # 若不存在下一個(gè)空白格,則返回 -1,-1def value(m, x, y): # 返回符合'每個(gè)橫排和豎排以及九宮格內(nèi)無相同數(shù)字'這個(gè)條件的有效值。 i, j = x // 3, y // 3 grid = [m[i * 3 + r][j * 3 + c] for r in range(3) for c in range(3)] v = set([x for x in range(1, 10)]) - set(grid) - set(m[x]) - set(list(zip(*m))[y]) return list(v)def start_pos(m): # 返回第一個(gè)空白格的位置坐標(biāo) for x in range(9): for y in range(9): if m[x][y] == 0:return x, y return False, False # 若數(shù)獨(dú)已完成,則返回 False, Falsedef try_sudoku(m, x, y): # 試著填寫數(shù)獨(dú) for v in value(m, x, y): m[x][y] = v next_x, next_y = get_next(m, x, y) if next_y == -1: # 如果無下一個(gè)空白格 return True else: end = try_sudoku(m, next_x, next_y) # 遞歸 if end:return True m[x][y] = 0 # 在遞歸的過程中,如果數(shù)獨(dú)沒有解開, # 則回溯到上一個(gè)空白格def sudoku_so(m): x, y = start_pos(m) try_sudoku(m, x, y) print('new_sudoku -> n', m) return m#################################################### 將結(jié)果繪制到原圖def draw_answer(img, contours, hierarchy, new_sudoku_list ): new_sudoku_list = new_sudoku_list .flatten().tolist() for i in range(len(contours)): cnt = contours[i] if hierarchy[0, i, -1] == 0: num = new_soduku_list.pop(-1) if hierarchy[0, i, 2] == -1:x, y, w, h = cv.boundingRect(cnt)cv.putText(img, '%d' % num, (x + 19, y + 56), cv.FONT_HERSHEY_SIMPLEX, 1.8, (0, 0, 255), 2) # 填寫數(shù)字 cv.imwrite('E:/answer.png', img)if __name__ == ’__main__’: t1 = time.time() train_set = training() img = cv.imread(’E:/test_image/python_test_img/Sudoku.png’) img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) sudoku_list, contours, hierarchy = find_dig_(img_gray, train_set) new_sudoku_list = sudoku_so(sudoku_list) draw_answer(img, contours, hierarchy, new_sudoku_list ) print('time :',time.time()-t1)
PS:
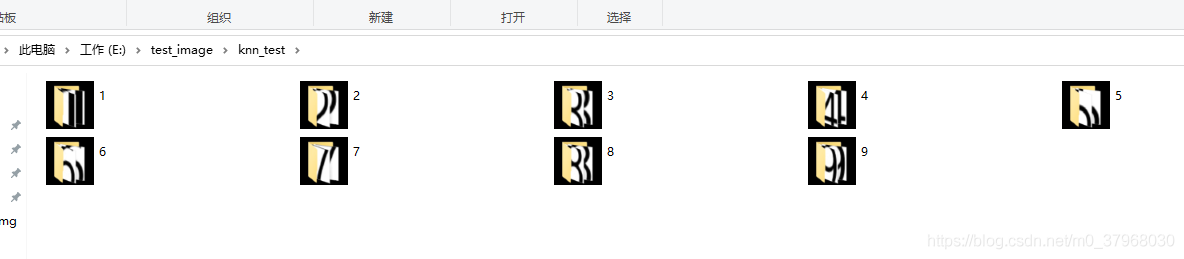
使用KNN算法需要?jiǎng)?chuàng)建訓(xùn)練集,數(shù)獨(dú)中共涉及9個(gè)數(shù)字,“1,2,3,4,5,6,7,8,9”各15幅圖放入文件夾中,如下圖所示。
到此這篇關(guān)于Python圖像識(shí)別+KNN求解數(shù)獨(dú)的實(shí)現(xiàn)的文章就介紹到這了,更多相關(guān)Python KNN求解數(shù)獨(dú)內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. Java 3D的動(dòng)畫展示(Part1-使用JMF)2. 解決docker與vmware的沖突問題3. IntelliJ IDEA設(shè)置自動(dòng)提示功能快捷鍵的方法4. Django中的AutoField字段使用5. IntelliJ Idea 2020.1 正式發(fā)布,官方支持中文(必看)6. Python基于jieba, wordcloud庫生成中文詞云7. asp.net core應(yīng)用docke部署到centos7的全過程8. 在vue中配置不同的代理同時(shí)訪問不同的后臺(tái)操作9. 簡體中文轉(zhuǎn)換為繁體中文的PHP函數(shù)10. Vue 構(gòu)造選項(xiàng) - 進(jìn)階使用說明
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備